研究方法 問題集錦
第9集
量化資料分析
臺灣師大圖資所
吳美美 <<社會科學研究方法問答錄>>
問題:什麼是分析單元?是放在統計原始資料表的什麼位置?
答:「分析單元」是指樣本的基本單元,通常放在量化原始資料表的y軸。
問題:信心水準是什麼?
答:有關信賴區間的解讀,很多人會計算信賴區間,但是如何解釋呢?例如一般的解釋通常說「甲候選人的支持度約有 95%的機率落在(0.539,0.601) 中」,但是這是一個錯誤的說法。
正確的說法是:對同一事件做調查 100 次,每次會得到一組數據,就會有100 個信賴區間,在這麼多的信賴區間中, p 約有 95%的機率落在這些信賴區間中,也就是說大約有 95 個信賴區間會包含參數 p. 因此 Example2 的結果,我們可以有以下的兩種說法:
我們有 95%的信心,甲候選人的支持率落在53.9% ~ 60.1%.
在 95%的信心水準下,誤差不超過 3.1%, 甲候選人的支持率為 57%。
http://web.ntnu.edu.tw/~494402345/CI/CI.pdf
問題 "曾看過幾篇量化研究的學位論文。那時總是主觀覺得,某些議題進行研究的價值究竟為何?(如有關大賣場的顧客忠誠度調查)因為從最初的緒論中,讀到背景、目的、問題後,其實心中已經產生數種可能性的論點。直接翻閱最後的結論,發現與心中所想差異不大。所以,量化研究其中一部分的功能,是否也算是在驗證心中所做假設,是否真實的方式?
答:問題中有關量化研究的敘述是正確的,量化研究的目的就是理論或某種觀察的驗證,也有很簡單只是純粹調查某些狀況,例如考試成績或是市場銷售量。通常量化研究除了一般的描述性研究,主要應用就是理論檢測。
問題:預測變項 vs 效標變項,有一些例子可以幫助理解嗎?
答:「預測效度」是「效標關聯」效度之一,「指測驗分數與將來效標資料之間的相關,常用的效標資料包括專業訓練的成績與實際工作的成果等。預測效度的鑑定,通常是運用追蹤的方法,對受試者的行為表現,作長期繼續的觀察、考核和記錄,然後以累積所得的實際資料與當初的測驗分數做相關分析,據以衡量測驗結果對將來成就的預測效力。」(http://terms.naer.edu.tw/detail/1312919/)
效標效度 Criterion Validity也稱為效標關聯效度 Criterion-related Validity ,可以作為「預測力檢定」(Prediction Model Validation),例如作為教育成效的測量工具,學科考試或各種心理測驗,透過分析某一項考試工具,看是否能夠準確預測樣本未來真實的學習發展成就。(http://tx.liberal.ntu.edu.tw/~purplewoo/methodology/Analy-TxStatisticsCanon-Validity.Prediction.htm)
問題:量化研究與選舉前的民意調查應該也有相當的關聯性。而不同單位所做出的民調有明顯差異,除了所抽取的樣本差異外,研究者、抽樣者、民調公司、背後金主的政治傾向,合該是影響甚鉅的變因。再加上以往看到不少研究會請學生寫問卷,但學生寫的狀況卻是非常糟糕。如此,量化研究耗費甚鉅的時間、金錢,究竟準確度能有多少?
答:有些研究報告的結果和閱讀者所想的差不多,那麼有可能會被質疑,不做研究是否也知道那樣的結果,沒有提出新知或驗證,那麼就表示不是十分成功的研究。
問題:"內在效度與外在效度比較抽象,是否有一套特定的方法去評估、判斷內在效度與外在效度面臨的威脅?"
答:內在效度和外在效度,簡單的說是研究的真實性和合理性,是研究者的自我警惕、需要注意的事項,這些項目可以做為研究者進行研究設計時的自我檢驗單。研究中很多都是抽象的概念,需要靠多觀察、體會和演練。
問題:在什麼樣的情況下,受訪者的回應是無效的呢?如有遺漏值,請問該問卷回應是直接無效,還是須設定遺漏值比例?
回答:有關遺漏值,可能不是考慮遺漏比例,因為如果是遺漏重要的、關鍵的研究變項,那麼那個樣本就應該是無效樣本。此外,樣本大小對於遺漏質的容忍度也不太一樣,因此可以說每個研究對於遺漏值的處理都不太一樣。
問題:「無回應」是指被研究者完全未做應答嗎?還是回應與問題不合適也可視為無回應(遺漏值)?我在想會不會是問卷有設定或限制受試者填答,例如會請受試者跳至某題填答,而前面無填答部分為問題不合適。
答:不是的。「無回應」是指被研究者完全未做應答,也就是遺漏值,要以遺漏值的方式處理。例如 "用負九(-9)表示沒有回答,用負八(-8)表示異常值,異常值的概念,可參考識別異常的觀察值<https://www.ibm.com/docs/zh-tw/spss-statistics/SaaS?topic=cases-identify-unusual-output,通常是指超出該變項值的範圍。
問題:在編碼表的「無回應」,有提出部分研究者會使用負值進行編碼,負九(-9)是指沒有回答,而負八(-8)則是指不適合,因此想問,那些研究者又是如何進行區分?可以用「其他」來進行代替嗎?有同學認為:電訪時會將未進行回覆或未被記錄到的資料視為無回應。而「其他」則是用於質性,編碼上會不太好處理,因此不會建議將其應用於量化研究。想問「無回應」是指被研究者完全未做應答嗎?還是回應與問題不合適也可視為無回應(遺漏值)?
答:對。「無回應」是指被研究者完全未做應答,也就是遺漏值,要以遺漏值的方式處理。例如前面所說 "負九(-9)是指沒有回答,而負八(-8)則是指不適合" 通常不適合是指該值超出平均值太多,也就是異常值,可以參考識別異常的觀察值<https://www.ibm.com/docs/zh-tw/spss-statistics/SaaS?topic=cases-identify-unusual-output
問題:假設檢定中關於型二錯誤時提到,越高的顯著水準會提高產生型二錯誤的機會,因此想問實際研究中,假設檢定出現型二錯誤的概率高嗎?
答:”假設檢定出現型二錯誤的概率高嗎?”這個問題的答案應該是因不同的研究個案而異吧? "越高的顯著水準會提高產生型二錯誤的機會",是在提醒我們 統計學上認為犯型 I 錯誤的後果相當嚴重,因此一般希望能將其發生的機率 (α)控制在一定的程度 (0.05 or 0.01),而型二錯誤的機率(β)為 1-α,應該是在指兩者的消長關係,建議研究多採用虛無假設。
問題:莖葉圖的使用時機?
答:莖葉圖基本上是提供一個簡單動手操作和眼睛可以辨識的初步資料分析的功能,能幫助研究者在動手畫記的時候就了解樣本的分佈,是否有常態分配。
問題:純看講義的莖葉圖介紹其實看不太懂,但聽了講解後,發現莖葉圖的概念很簡單,而且很適合國小高年級學生使用,想在新學期中教給六年級學生使用。
回答:太好了!這是很便於使用的研究分析工具!
問題:莖葉圖要怎麼決定換行呢如:2.112233怎麼決定要不要換成:
答:莖葉圖的特性就是將個位數都寫在一條線上,如果寬度不夠,可以將6-9另寫一行,可以仔細再看一下定義喔。
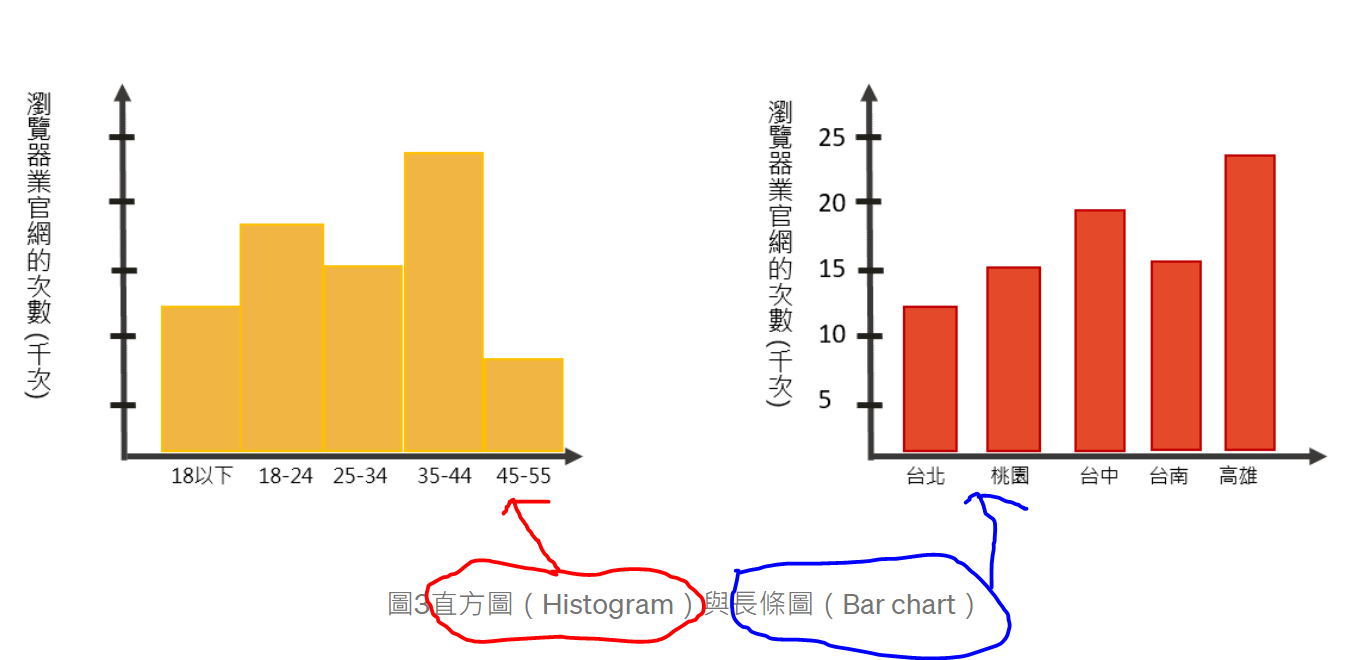
問題:在量化資料分析中介紹到,通常將自變項設在x軸,依變項設於y軸。國小教育中從四年級開始介紹圖表資料整理概念,大部分的表格遵循量化資料分析,但我記得小學階段內有種特別強調的長條圖剛好就是將自變項設在y軸,依變項設在x軸。不知編審教科書的委員或教授們有無考量量化資料分析的常規呢?另外我也是閱讀完本章才了解到長條圖與直方圖的差異,以及折線圖通常會跟著直方圖而非長條圖。
答:太好了!能學習到知識和其間的邏輯,就能辨識資料的對錯。
問題:介紹到卡方檢定時,講義中提到2X2表格的自由度為(2-1)X(2-1)=1,此自由度是何意義?自由度的公式是NXN表格=(N-1)X(N-1)嗎?
答:這個問題很好。通常提到自由度,就可以聯想是在討論樣本數或是組別,假設有3個數,加起來10,其中只能有2個數可以在10的範圍中任選,第3個數被設定了,所以自由度是3-1=2;若有9個數,自由度就是9-1=8,這個概念很好理解,公式就是(n-1)。在卡方檢定中,自由度的計算是欄數和列數各減1相乘,也就是欄和列的自由度相乘,就會得到該項卡方檢定的自由度。卡方值事先根據自由度(k值)和機率(p值)計算出來,通常卡方分布表會附在統計書的附錄中。一般卡方值(χ2)越大,p-value越小,則可信度越高;通常用p=0.05作為閾值,即95%的可信度。
問題:想請問老師檢定假設方法中的t檢定,或我想比較a群體和b群體某種特性的差異,但假設a群體有140人,b群體只有20人,這樣<30的b群體可以拿來跟a群體作比較檢驗嗎?謝謝!
回答:一般而言是不行的。統計分析的最小樣本,不可少於30個。
問題:在〈非反應式研究和次級資料分析〉講義p33:內容分析中,無法從內容去推論對讀文本的人所產生的影響,只能利用調查研究的相關性邏輯顯示出變項之間的關聯性。這段我不太理解,是指:我們在面對內容分析的研究成果時,也要思考到研究者本身對文本詮釋的影響嗎?比如說研究者A對文本的內容分析,其實也受到他所持的理論和背景影響這樣?
答:應該不是的,研究分析都主張研究者要盡力去除個人觀點,只從文本邏輯去找線索。如果研究被研究社群所接受,也就是說研究社群就假定這位研究者有做到去除個人所持的理論和背景之影響。
問題:在判斷統計檢定的方法 有/無母數參數,母數的定義是什麼?
答:母數就是母群體(population)。
問題:請問為何博士生的量化問卷研究耗費時間比碩士生多上許多?是因為要將問卷無中生有,經過較嚴格且漫長的前測嗎?
答:我不知道「博士生的量化問卷研究耗費時間比碩士生多上許多」是指問卷設計的時間嗎?應該是花在理論建構吧!嗯老師有解釋「前測」通常是用在說明前、後測,也就是實驗設計才有前、後測,你這裡是指pilot study 前導研究嗎?
問題:請問老師如何判別何時需要的假設方法呢? 不知我這樣解讀對不對:
類別變項+類別變項-> 卡方檢定
連續變項+連續變項-->皮爾森相關係數、斯皮爾曼等級相關
類別變項+連續變項-->t 檢定
三個以上的變項 --> ANOVA、迴歸分析"
答:很棒!你的解讀完全正確。不過問題可以酌修一下,將「如何判別何時需要的假設方法呢」 改為「如何判別何時需要的假設檢定方法呢」 這樣表達會更完整。
統計檢定的計算方法:無平均數,只有出現頻率、次數的變項的檢定公式是卡方檢定;可以計算平均數的變項,就用t檢定和Anova檢定。這些概念在量化分析的單元,有詳細的圖表解釋,更容易理解。
問題:為什麼類別變項只能用卡方檢定呢?
答:因為類別變項,不能計算平均數。統計檢定是靠數學運算,而測量尺度會影響數學的計算方法。例如類別變項,只有等於和不等於的關係(如下圖),例如男、女,在統計的編碼簿中通常以1、2代表,類別變項雖然以數值表示,但只是代號,不能加以運算,只能計算類別的出現頻率,也就是次數分配(frequency),也因此不能算平均數。而順序變項只有大於和小於的關係(例如名次),等距變項可以加和減(例如溫度,20度比10度溫度高了10度),比率變項是等距且有絕對0的測量尺度,可以乘和除(例如年齡和成績,40歲是20歲的2倍,80分是40分的兩倍)。等距和比率尺度是連續變項,有加減的特質,才可以算平均數。

問題:直方圖和長條圖的使用時機有何不同?
答:直方圖(Histogram)是一組連續數字(Numerical)資料的次數分配圖。直方圖的組距之間有順序性,描述的是連續性的資料(如年齡、收入等)。直方圖可以看出中位數、眾數的大約位置,以及資料在各區間是否存在缺口或是出現異常值。長條圖(Bar chart)雖然同樣是次數的呈現,但其橫軸為類別(Categorical)項目,長條圖的組距之間,並未有一定的排列順序,可根據所需進行調整(如地區由北到南排列,或是由南到北排列等),條狀之間的間距不可相連(如下圖)。
問題:量化研究為什麼要注意樣本數?
答:通常樣本量小時,標準誤很大,樣本均值和總體均值差異很大,樣本的代表性很差。因此提醒研究者,量化研究要注意樣本數。
問題:想更具體了解講義P12:「當要對態度問題進行編碼時,若問題是採相反方向,則編碼就可以倒轉過來」的意義。
答:反向題能測試答題者態度是否一致、專心做答外,在心理測驗中更經常使用反向題,以正面及負面的表述來測量同個概念。而反向題不一定只是單純加了否定詞,也不適合出現雙重否定。舉例一個測量暴力傾向的量表,正向題如:我生氣時經常考慮透過暴力來抒發情緒;反向題可以是:我生氣時不會考慮透過暴力來抒發情緒 / 比起暴力,我更經常透過其他方式抒發情緒。後者即不含否定詞,但仍為反向題,須反向計分。使用反向題的原因是量表中若多為正向題,雖易於閱讀但會使得受試者思維依著一定的模式作答。而編碼倒轉的意思即是反向題在統計分數時,該題必須反項計分 (得分=編碼最大值+編碼最小值-受試者選擇分數)。
問卷問題反向的原因和注意事項:
- 要注意作答者可能會以為問卷設計不良
- 在心理測量學領域中,很多學者開始建議正反向題混合使用的方法。其好處在於:能夠幫助篩選出不認真作答的受試者,如果不論是積極還是消極的描述,被試全部都選擇了認同,就可能存在不認真回答的嫌疑;正反向題混合會消耗受試者更多的認知資源,因此可以讓被試更加投入,減少習慣反應。因此不管是對默認好評還是差評的受試者,正反向題混合都可以降低這種習慣反應的影響。
問題:不太理解多因子的部分。假設上課成功老師要上好,學習者理解、熱心、花時間理解為三個自變項,依變項為學習成果,例如單元成績、期末作業、功課等,則分析即為多因子變異數分析。
答:多因子是指多種影響因素,學習者理解、熱心、花時間理解為三個自變項但仍然是學習者的因素,若是加上教材因素、教師教學因素,就可以稱為多因子變異數分析。
以下研究請參考:
問題: 進行假設檢定建立假設(虛無及對立假設)後,是不是接著要決定用什麼程度的機率拒絕虛無假 設呢? 如何決定統計檢定的顯著水準呢?
答:根據一般的統計教材,越是不能犯錯的科學實驗,例如藥學實驗,顯著水準通常很高,>=.0001 就是10000個的錯誤容忍量需要小於1個。一般社會科學的統計顯著水準是 .05 /.01 /.001
社會科學因為干擾因素比較多,通常設在>=.05 或.01。
>=.05表示100個中可能的誤差,小於或等於5個;
>=.01表示100個中可能的誤差,小於或等於1個
注意小數點前面的0通常省略,那是因為p值不會大於1
請參考。
問題:運用非反應式的次級資料時,如果不同的資料庫針對相同的問題有不同的數據,應該以哪個單位為主呢?例如政府機構調查失業率,天下雜誌社也調查失業率,兩者數據有差距時,應該如何解釋呢?
答:研究方法中有多元檢測法 (triangulation) 就是說一個研究問題,可以透過多組資料收集來檢視研究結果。兩者有差距時,就再用第三組資料來檢驗。
問題:統計的量化數字分析難度較高,希望老師可以再給我們一些統計範例做指導,可以更清楚分析數據的方式及如何詮釋產生的統計結果。
答:好的。統計範例老師都有錄製詳細操作步驟,你希望看到哪方面的範例?可以提出具體一點的需求嗎?我們來補充。
統計次級資料練習回饋
學習心得
「此單元的量化研究,或許因為沒有統計學的基礎,讀起來備感吃力,很多辭彙、計算方式等都還很陌生。但SPSS對研究生而言是很重要的統計分析軟體,所以鞭策自己一定要多加閱讀以快速上手,希望將來能自由運用在自己的學術產出。」
「此次的學習,感覺就像是在複習上學習所學的統計學,在聽講時會不斷勾起回憶,之前在寫閱讀文獻時,常常會看到許多不同方式的統計檢定,有時其實會不是很瞭解,透過這次的課程,我更清楚每個研究者們選擇該檢定的主要原因為何,此外,老師所推薦的師大圖書館統計檢定指引系統,對我來說更是一大幫助,透過該系統,我得以瞭解自己的研究可應用何種統計檢定。
「這週內容真的好多,雖然在閱讀聽講的時候覺得很累,不過覺得有吸收、有理解時就很有成就感;統計課是拉長到一學期,每星期學習的,雖然內容比較深入,也要去算題目,但這樣濃縮各種概念,一次綜觀學習也很不錯,之後還是要多閱讀案例並實際動手操作。
「本週的課程就像是濃縮一般二學期或一學期的統計學課程,將其中的精華一次呈現。內容很扎實,不過我認為學統計好比學語言,可能會需要多一些時間累積,不論是要理解專有名詞及其定義、公式的推導等,尤其是對於初階新手或是概念掌握仍不足的學習者而言更是如此。而若在學習過程中,沒有時常接觸與練習,恐怕也難以真正掌握並活用這項工具。
「這次的課程量真的很多,如果沒有先學過統計的話,我覺得應該會很難消化,透過這次的講義讓我重新溫習了有關統計的相關概念,但是覺得比起文字的敘述,統計應該透過實際的舉例以及練習,會更好能理解。
「我還沒修過統計課,所以對於本單元中介紹的統計概念和分析方法認識比較少。經過學習後印象最深的是編碼簿的部分,學到怎麼將問卷變項編碼,以及編碼時需要注意的事項。雖然對於統計分析方法還不完全熟悉,但是學到研究者需要根據資料特性或是變項數量來選擇方法,因此即使採用次級資料,將資料適當地處理並了解其中的內容是必要的。我覺得統計分析時進行的運算很複雜,現在有軟體可以直接操作並生成圖表,真的很方便。
「過去都是以數學的角度學習統計,這次以社會學研究的角度再次看它,儘管最後幾頁的假設檢定方法仍需時間消化,但結合了實例解說和表格的整理,就覺得其實統計技術在使用上也沒那麼困難了。
「因為統計課本常以專有名詞做撰寫,每次理解一個詞彙中還要先理解另一個詞彙的意義,像是標準誤,我就花了非常多時間才搞懂其意思,一直在思考跟標準差的不同,而這份講義其實簡單說出就是【樣本平均數的標準差】,強調出樣本後,覺得非常好理解。還有像是型一錯誤、型二錯誤,雖然統計課本有說明兩者錯誤,但講義表達的方式比較白話,馬上可以比較出其不同的地方,型一是以為有差異但其實沒有,型二則是以為沒有差異但其實有。
[很贊同妳說的,理解一個詞彙要先理解另一個詞彙,這說法對研究方法的許多概念而言,真是傳神呀!]「講義第91、92頁的整理非常清晰,這樣的分類功能也對統計初學者很友善,可說是當初學統計時相見恨晚的資訊。但現在又整理一次,對統計檢定的應用有更深刻的學習。
「原本希望有整理檢定方式的種類和判斷依據,但發現講義的p.89-92有整理大表格,甚至學校有系統可以協助統計指引,非常方便及感謝。
「其實不光只是本週的課程,在這門課中要求非常多實作練習的部分,也是讓大家對課程內容熟悉的關鍵
「老師在課堂上提點我們:「先了解資料,再來才是計算。」,這句話點出了本次練習的重點,過去大學曾上過的統計課裡,多數老師講求運算的方法與結果,並未特別著重於為何要使用這些方法,因而使我未能注意到資料集與項目的重要性。透過本課程的練習,終於發現自己應加強的方面在哪裡。
「老師說的理解和思考,真的很重要,很有幫助:
關於描述問題的方式一定要很謹慎,小心仔細的斟酌字句,「了解」放在開頭的話是帶有目的的行為,是敘述的話,不能在後面加上問號變成問句當成問題,我學習到用字遣詞要準確。
在實際練習SPSS時,看著問題以及資料,我一開始很不知所措,不知道該從何下手,想起老師說的要理解和思考,就去想這些資料到底在記錄什麼,然後題目要問什麼,看了老師的影片後,再去試著動手操作。...實際操作過一遍,SPSS沒有想像中難用,...這次最後一題要檢定年代[度]和經費是否有統計上的顯著相關,我使用了ANOVA檢定,...。實際操作過後,才對之前學的東西有更深刻的感受,也發現自己還有很多不足的地方,收穫許多。
「藉由課程中的小組分享,澄清了原始資料(Raw Data)及其他已進行整理過後的資料的區別;往後在進行既存資料的查找與下載時,也會更加注意它的類型為何。透過幾組的案例,也更加明白編碼簿的使用。
研究問題,若以行為動作作為開頭(e.g.探究),就是敘述句,不是疑問句。
在進行SPSS練習時,由於版本不同,有些操作需要調整(但差異不太大);其實在操作上沒有什麼太大的問題,最需要練習的部分仍是統計檢定方法的選擇(與解讀),雖然有進行了範例實作,但進入到後續的練習時,因對各種檢定尚不熟練,加上需要對資料集進行篩選與整理,因此仍對於檢定方法的選擇和結果有些不太確定。
補充說明學習要領
學習統計和學習任何新東西是一樣的,需要了解其中的特質和規則。
特質:量化分析,學習統計分析,要有研究的邏輯理念和操作工具的技能,就如同捏陶藝練習一般…,心中要先經營,有預期產品的設計構想,然後也要操作塑泥機器,剛開始機器不要開太快,才能慢慢成形。
規則:了解統計分析必要的基本配備,編碼表、原始資料表、基本統計結果表或敘述統計分析,以及最後的推論統計分析
基本概念:
變項的類型(變項的值(value)是屬於連續變項或是類別變項和選用的檢定方法有關,需要區分)
需要先檢查標準差(SD)是否在合理的範圍(如果SD值太大,表示樣本特質離散情形太大,樣本不具備常態分配,表示這群樣本可能缺乏母群的代表性,或是樣本太小) 因此敘述統計是必要的過程;
分析單元的概念,簡單了解就是樣本的呈現,分析單元放在第一欄,其他各欄依序是各個變項。



沒有留言:
張貼留言